How to Access Data from Public Databases
Morgan Feeney, Leighton Pritchard
2021 Presentation
- A wealth of information is freely available in public databases, and can be searched and accessed for use in your project.
- Specialised databases are available for different purposes
- Each item of data deposited into a database is assigned a unique identifier called an accession number.
- Deposition of research data in public repositories is often a requirement for publication
- Databases are not equally authoritative: some are databases of record, and not all are curated for quality control and accuracy.
This part of the workshop aims to introduce you to several ways of accessing data from public databases.
1 Introduction
Many, if not all, projects will involve the use of data from publicly available databases. You may be analysing these data as the main focus of your project, or comparing data you have generated with publicly available data (e.g. comparing the 16S rRNA gene sequence from an organism you isolated with 16S rRNA gene sequences deposited in the NCBI database.)
Databases provide an essential service in storing, organizing, and allowing researchers to easily search and access data. Most journals (certainly all reputable journals!) require researchers to deposit any data generated as part of a publication in the appropriate public database.
Some example journal requirements for data deposition (click to expand)
2 Where can we get public data from?
There are specialised databases for particular types of data. The databases that are relevant to you will depend on the specific task you are carrying out. For example, if you are trying to find the 3D structure of your protein of interest, the appropriate data will be stored in the Protein Data Bank, but not in the NCBI Genbank database (this database stores nucleotide and amino acid sequence information).
Many public databases are connected by database crosslinks (also known as xlinks). Some of the most useful databases, such as UniProt, are valuable not just because they contain useful data but because they cross-link between so many other databases to connect very different data types for easy integration of datasets.
Most databases can be accessed interactively through a web-based interface. Many can also be accessed via the command line, or programmatically (not covered in this workshop).
2.1 Repositories of record vs domain-specific curated (or not) resources
Primary databases usually provide experimentally-derived data, such as the 3D protein structures solved by X-ray crystallography, NMR or Cryo-EM, whose data are deposited at the PDB. Similarly, the Sequence Read Archive (SRA) stores raw reads obtained from high throughput sequencing. and The Cancer Genome Atlas (TCGA) provides access to genomic, transcriptomic, and clinical data for a range of cancers.
Both the PDB and SRA are Repositories of Record. In addition to being stores of experimentally-derived data, they are internationally recognised as the scientific community’s main repository for their datatypes. As such, journals may require that any suitable data is deposited in these repositories as a condition of publication. These kinds of repositories are required to be stable over decades, so are often funded at a national or international level.
There are a large number of subject- or organism-specific databases. These may contain primary data, but often contain data derived from analysis of primary databases, or integrate data from multiple sources to provide a comprehensive view of a particular topic. For example, the Comprehensive Antibiotic Resistance Database (CARD) is a curated database of known resistance determinants and associated antibiotics. Curation can increase the reliability and trustworthiness of a database, as problematic data may be excluded and only well-evidenced data included. However, curation is time-consuming, and these databases may be smaller than comprehensive databases that have less quality control.
UniProt, Swiss-Prot and TrEMBL: Curated and Uncurated (click to expand)
The UniProt database comprises two main sequence databases under the name UniProtKB (UniProt Knowledgebase): Swiss-Prot and TrEMBL. The TrEMBL database contains all translated protein-coding sequences from public nucleic acid databases. The vast majority of these translated sequences are predictions - they have never been experimentally studied, or their existence confirmed. By contrast, the Swiss-Prot database contains only non-redundant, manually annotated protein sequences. Each sequence in Swiss-Prot carries an evidence code to indicate the strength of experimental evidence for the existence of the protein.
TrEMBL for every protein in Swiss-Prot, and the ratio increases with every version of the database.
Watch out for unmaintained sites!
Major databases are continuously updated and well-maintained. For example, the databases in the International Sequence Database Collaboration (INSDC: Genbank, EMBL, DDBJ) automatically update one another with new data collected daily.
However, not all databases are equally well-curated. Some will persist, even after they are no longer curated - and thus may contain out-of-date information, or not have the latest updates. Caveat emptor…
Database versioning
Database contents change over time as new data is added, redundant or incorrect data is removed, or otherwise modified. It is important for reproducibility, therefore, to report the version information appropriate to your dataset.
Some databases, such as UniProt, provide a complete history for each database entry. Other databases provide a version number for each accession, such as the number following the decimal point in GenBank records like GCF_007858975.2. Others may provide a release version number for the database as a whole - and GenBank does this also, every two months (GenBank releases). Some databases provide no version information, and these should be reported with a date when the database was accessed.
2.2 Different sites may have very different access/functionality/searching
Most databases can be searched by keywords, though the search interfaces may vary. Many sequence databases will allow you to search by sequence similarity (e.g., BLASTP to search for proteins similar to a query protein).
Pay careful attention to your search terms!
As with any query to a computer database, keyword searches in biological databases are sensitive to typos or spelling errors. For example, searching UniProt for “lipaomide dehydrogenase” retrieves 0 results, while the correctly spelled search “lipoamide dehydrogenase” retrieves thousands of results.
3 What are accession numbers and how can we use them?
Records deposited into a database will be assigned a unique identifier, called an accession number. An accession number will always refer to the same record.
The format of accession numbers varies between databases:
- Genbank acccession: BAD70110.1
- UniProt accession Q5SLK6
- PDB accession 2EQ7
Sometimes it may be necessary to update a particular database entry when new experimental data becomes available (e.g., to correct errors or add new information about the sequence or molecule.) The previous database entry will be preserved (it is part of the permanent scientific record!), but an updated version will be published to the database, with a new version of the accession number.
For example, the sequence of the well-studied model organism Escherichia coli (MG1655) was deposited to Genbank under the access number NC_000913.1 in June 2004 and this record can still be accessed at https://www.ncbi.nlm.nih.gov/nuccore/NC_000913.1. However, since then a few errors in the sequence have been corrected, and the annotation updated: the current record (at time of writing) has accession number NC_000913.3 can be found at https://www.ncbi.nlm.nih.gov/nuccore/NC_000913.3.
Note that the old version has a warning note attached to it and a link to the current version.
Although an accession number is sufficient to identify the record, the version number should also be cited.
4 How do we cite data from public databases?
Give the URL to the database, the accession number(s) of the data used, and state the date of access or version number (if available).
5 Examples of how to search public databases and retrieve information
To look at how you might use public databases in the context of a capstone project, we will take the example of a beta-lactamase (carbapenemase) called NDM-1, which makes bacteria resistant to a broad range of beta-lactam antibiotics. The spread of bacteria carrying these carbapenemase genes is a major public health concern.
Click to toggle an example of how to search the NCBI databases (example of how to search using a keyword query)
Our first task is to find the NDM-1 amino acid sequence. To do this, we will search the NCBI databases (starting from https://www.ncbi.nlm.nih.gov/). [The search bar is at the top of the page (arrow). Note that we can choose which of the NCBI databases we would like to search (arrow) - for this example, we will keep the default (all databases), but we could equally choose to search the Protein database - since the protein sequence is what we are looking for.]
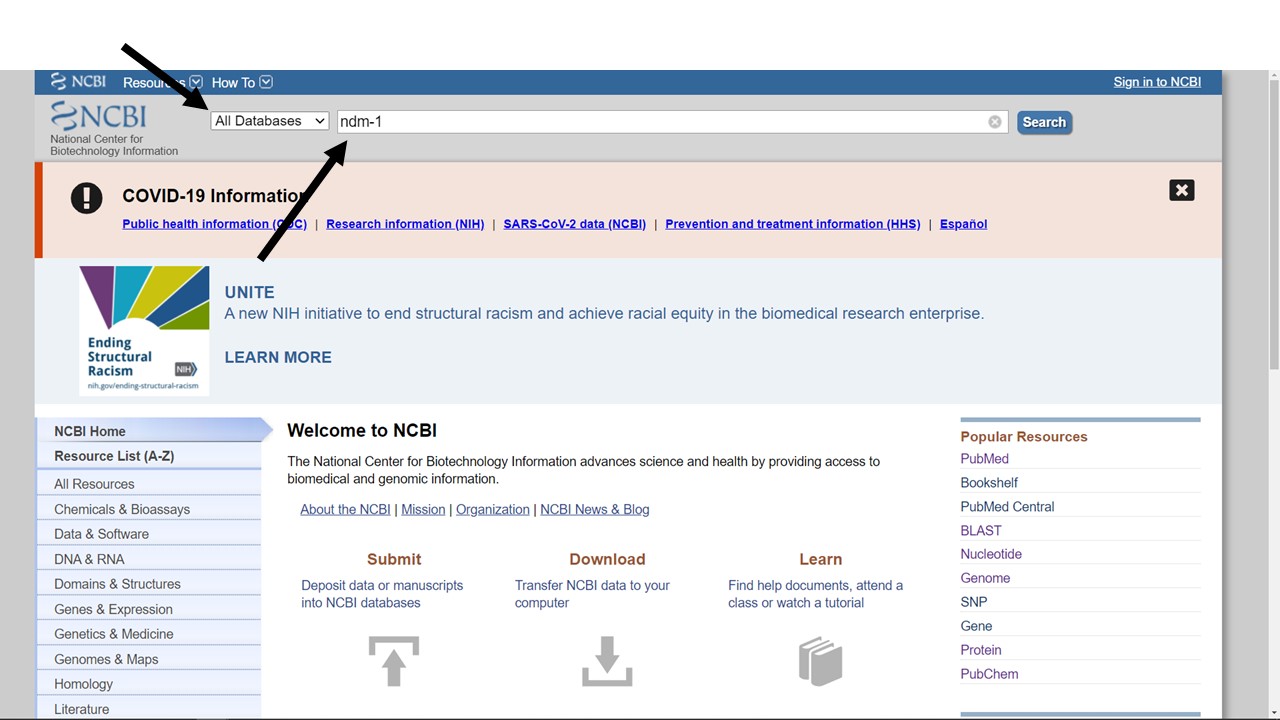
Figure 5.1: An NCBI search for ndm-1
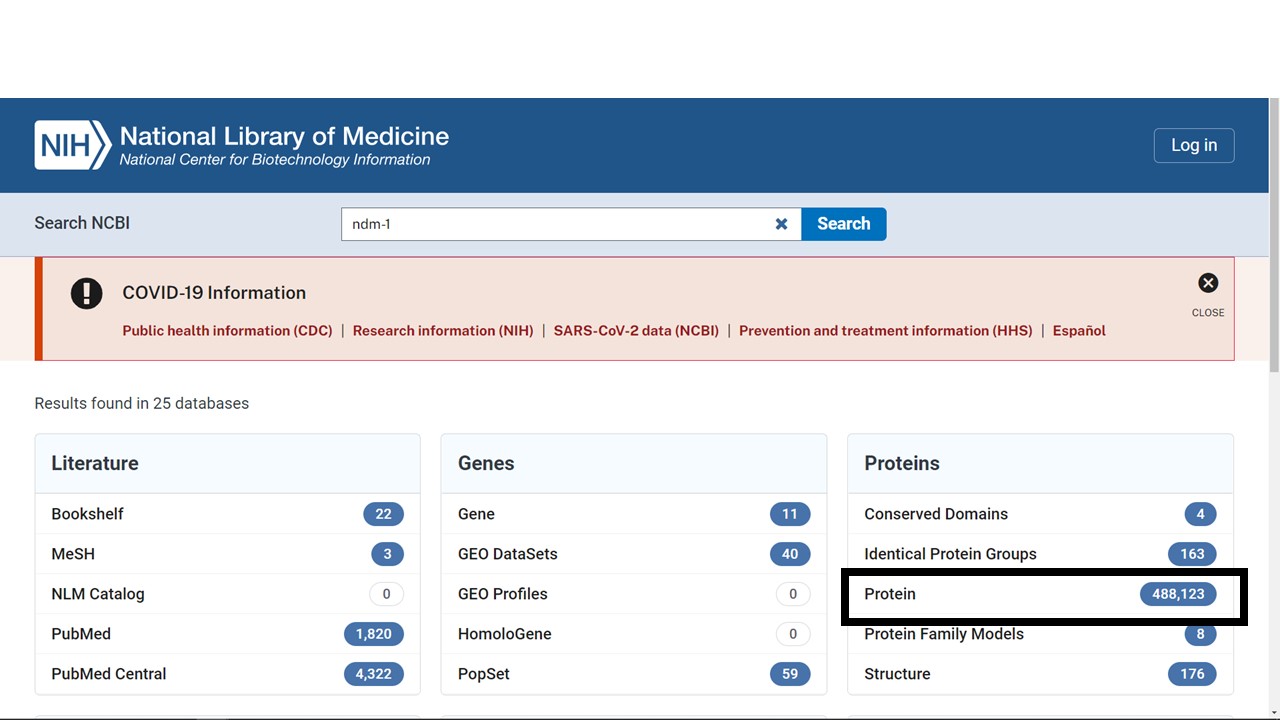
Figure 5.2: Results page for an NCBI search for ndm-1
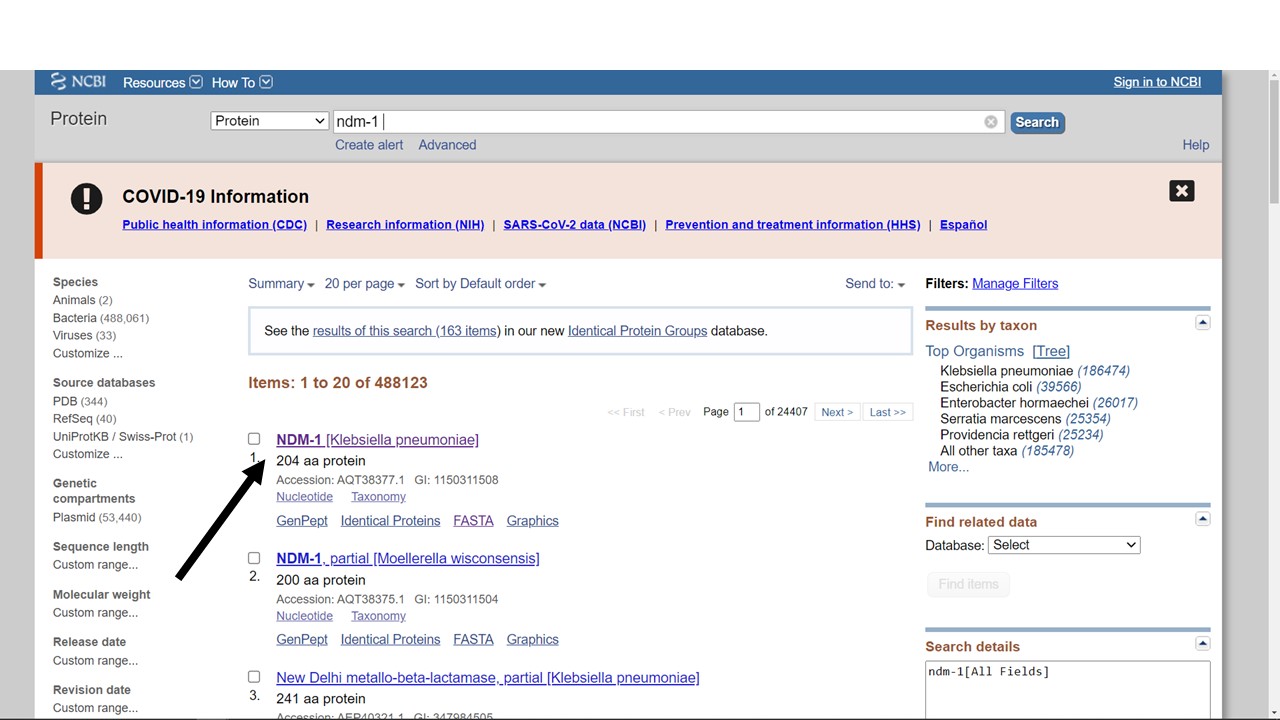
Figure 5.3: Protein database hits from an NCBI search for ndm-1
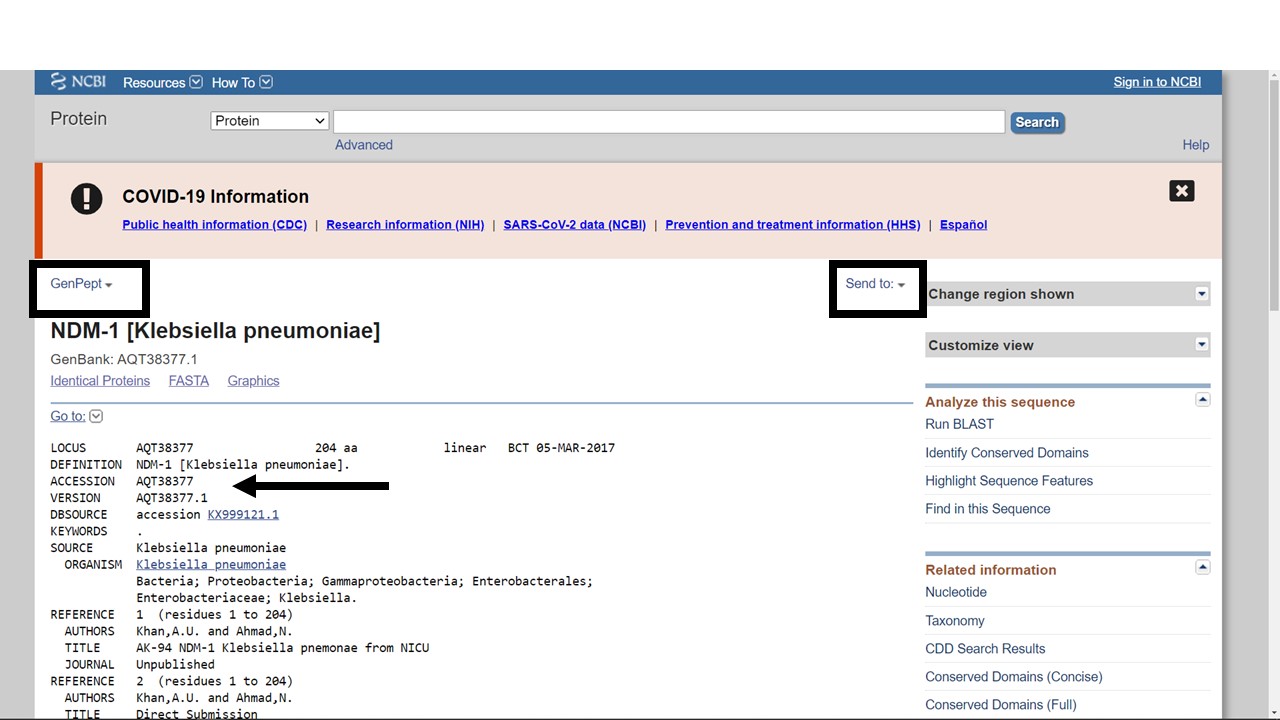
Figure 5.4: Klebsiella pneumoniae NDM-1 NCBI page
Click to toggle an example of how to search the Comprehensive Antibiotic Resistance Database (CARD) (example of how to search using a keyword query with autocomplete)
We might also want to find information about which other species have been found to have NDM-1, or sequence variants that have been observed in different strains. For this, we will turn to the CARD database (https://card.mcmaster.ca/).
The search bar for the CARD database is at the top right hand corner of the page. Note that as we start typing in our “ndm-1” query, a drop-down list of autocomplete options appears (arrow). We select and search for the option we want.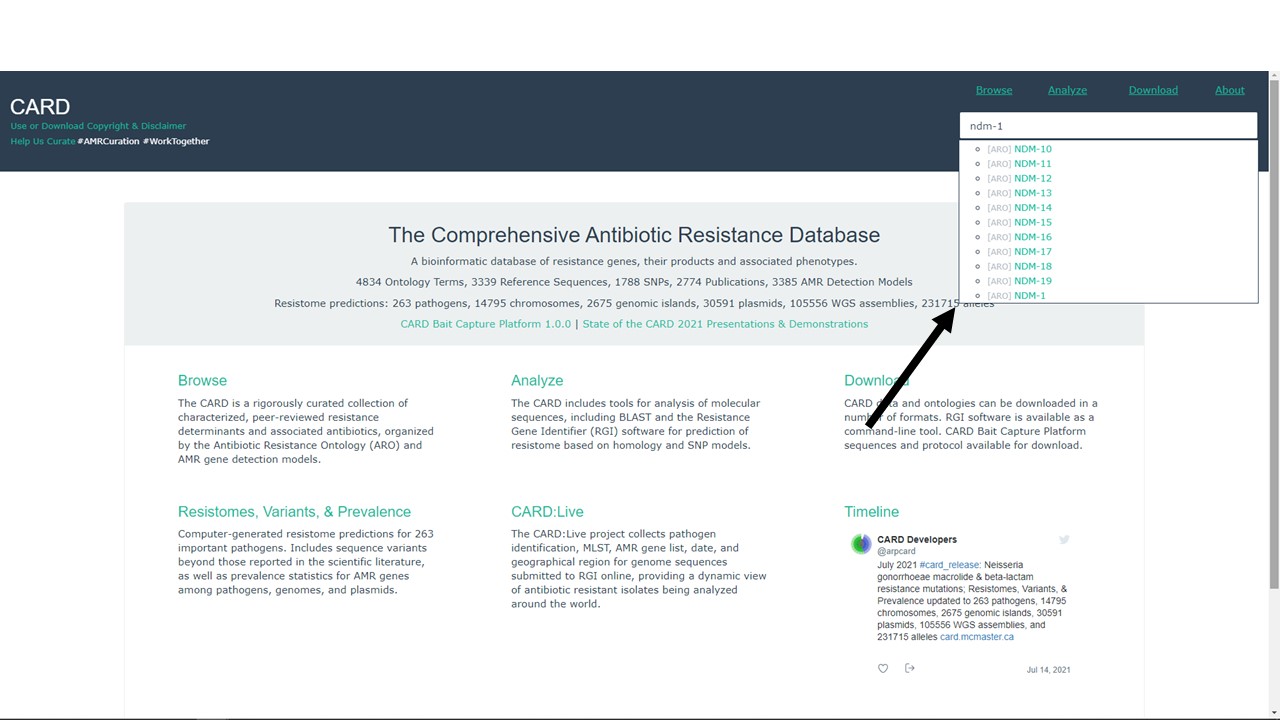
Figure 5.5: A CARD search for ndm-1
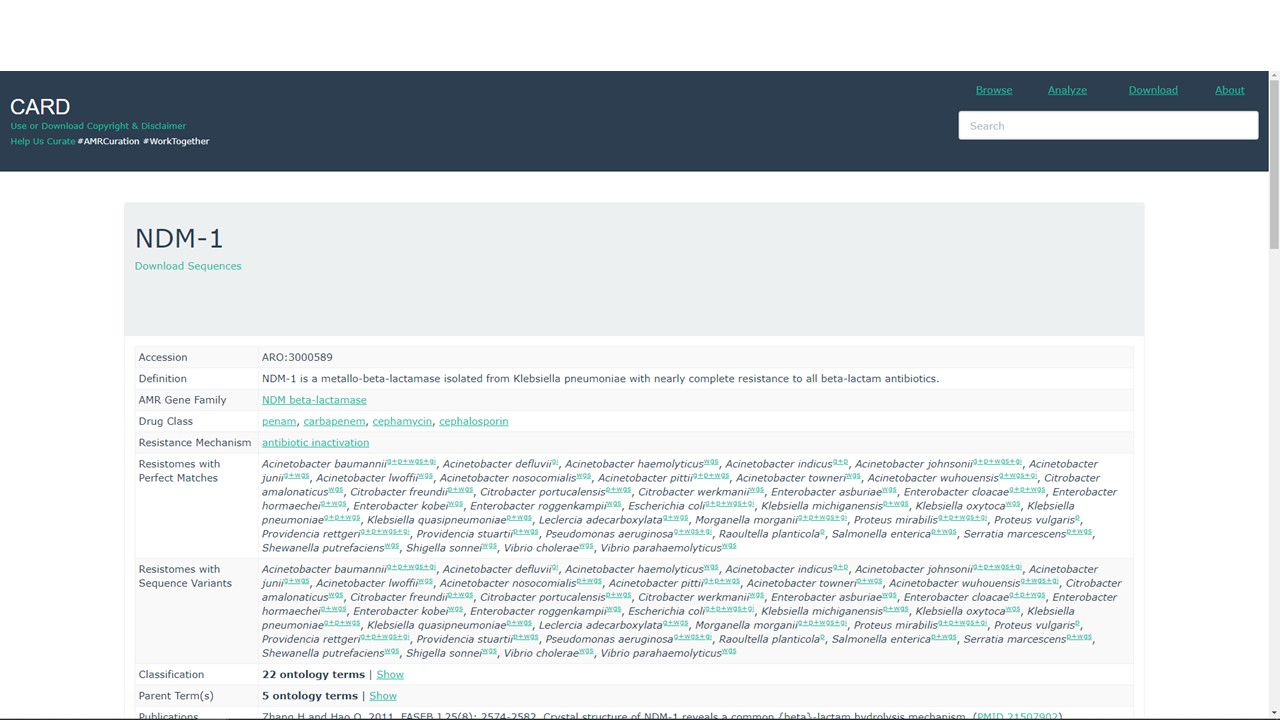
Figure 5.6: ndm-1 results page from CARD search
Click to toggle an example of how to search the Protein Data Bank (PDB) (example of how to search using a keyword query)
We also want to find the 3D structure of the NDM-1 protein. To do this, we turn to the Protein Data Bank (PDB) at https://www.rcsb.org/.
The search bar is at the top right-hand corner of the screen (arrow). We enter our “ndm-1” query and hit search.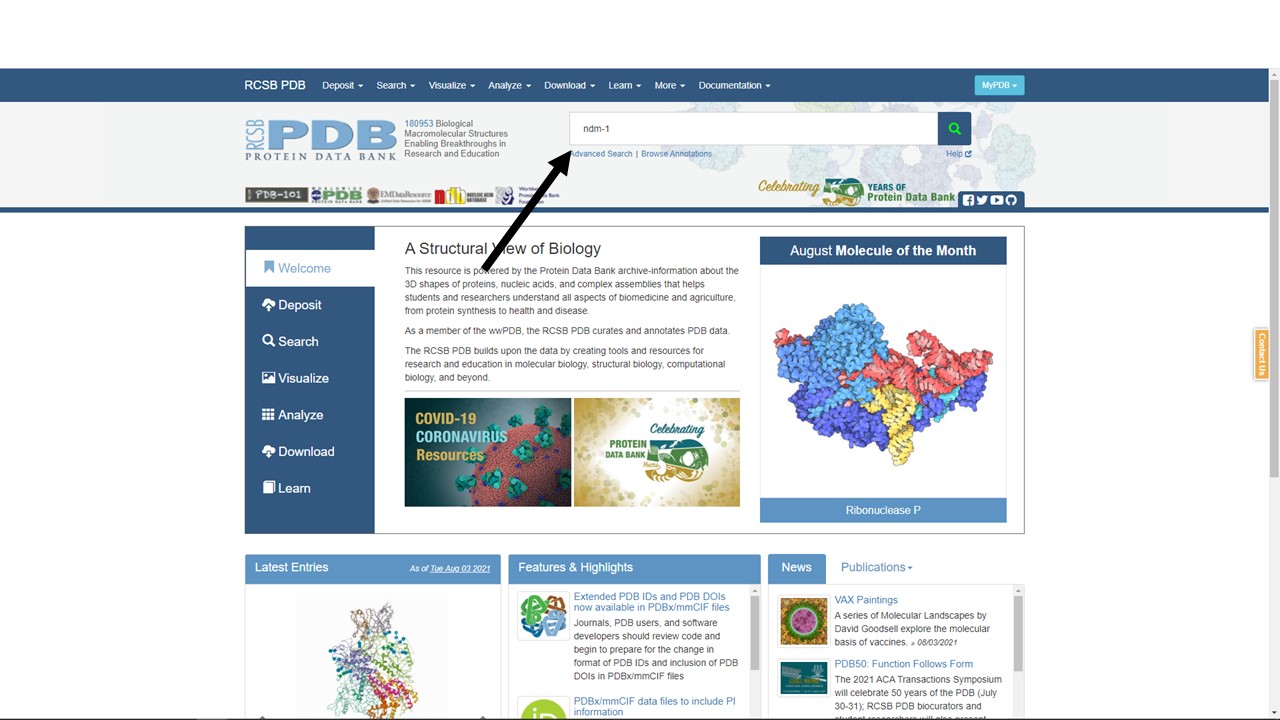
Figure 5.7: A PDB search for ndm-1
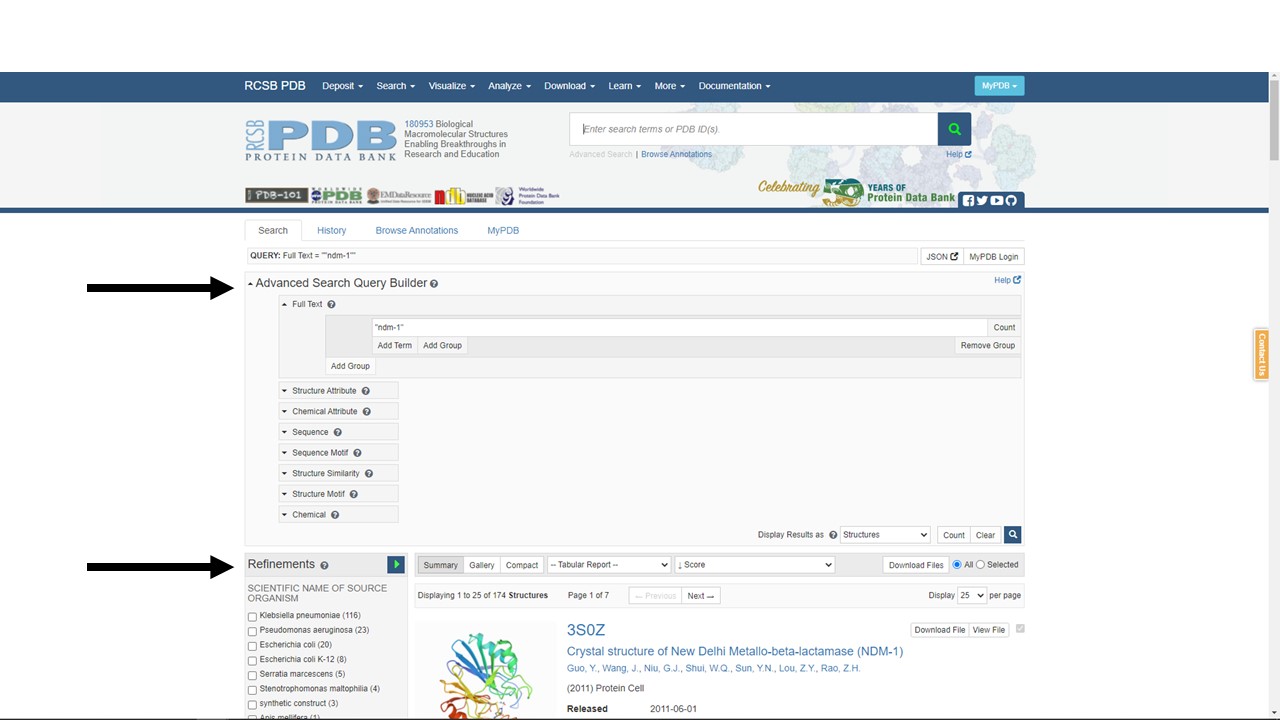
Figure 5.8: PDB search results for ndm-1
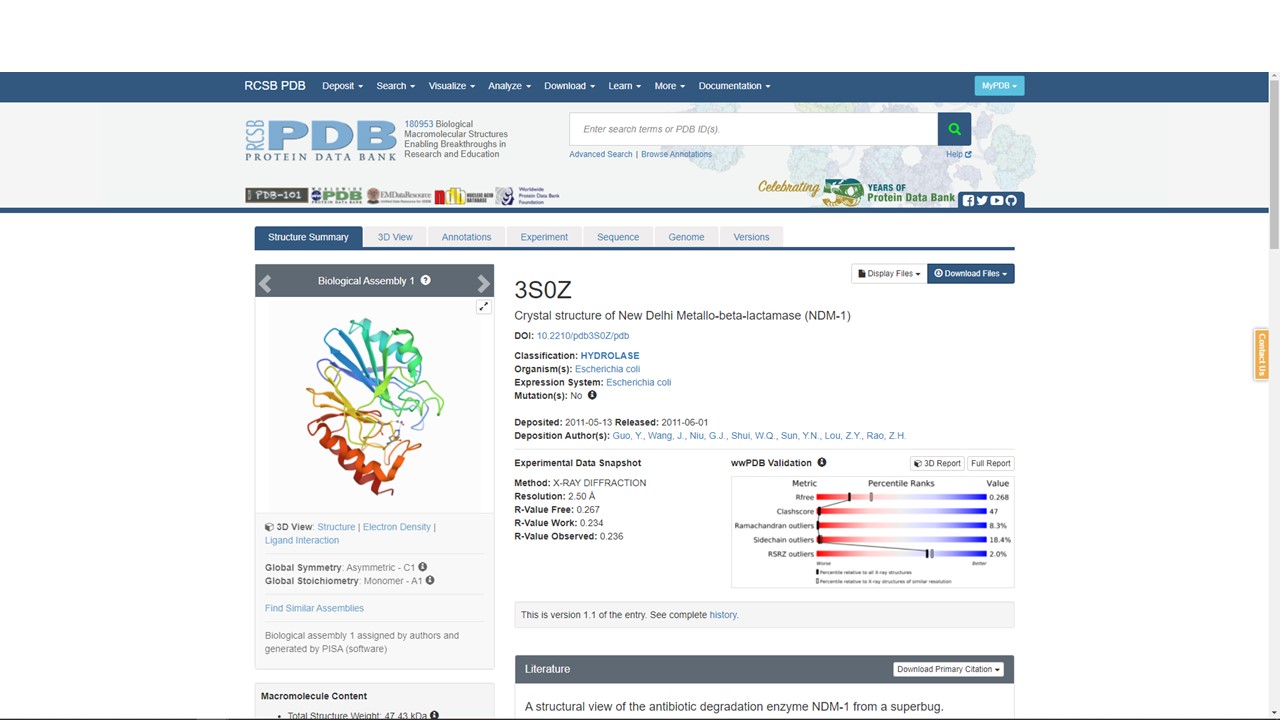
Figure 5.9: PDB page for NDM-1
Click to toggle an example of how to search the Pfam database (example of how to search a database using a sequence query)
Having learned about the sequence and structure of our NDM-1 protein, we now want to learn about any related proteins. To do this, we will turn to the Pfam database (a database of protein families), at http://pfam.xfam.org/.
There are a number of different ways to search the Pfam database (centre of the page), including by keyword, accession number, or protein sequence.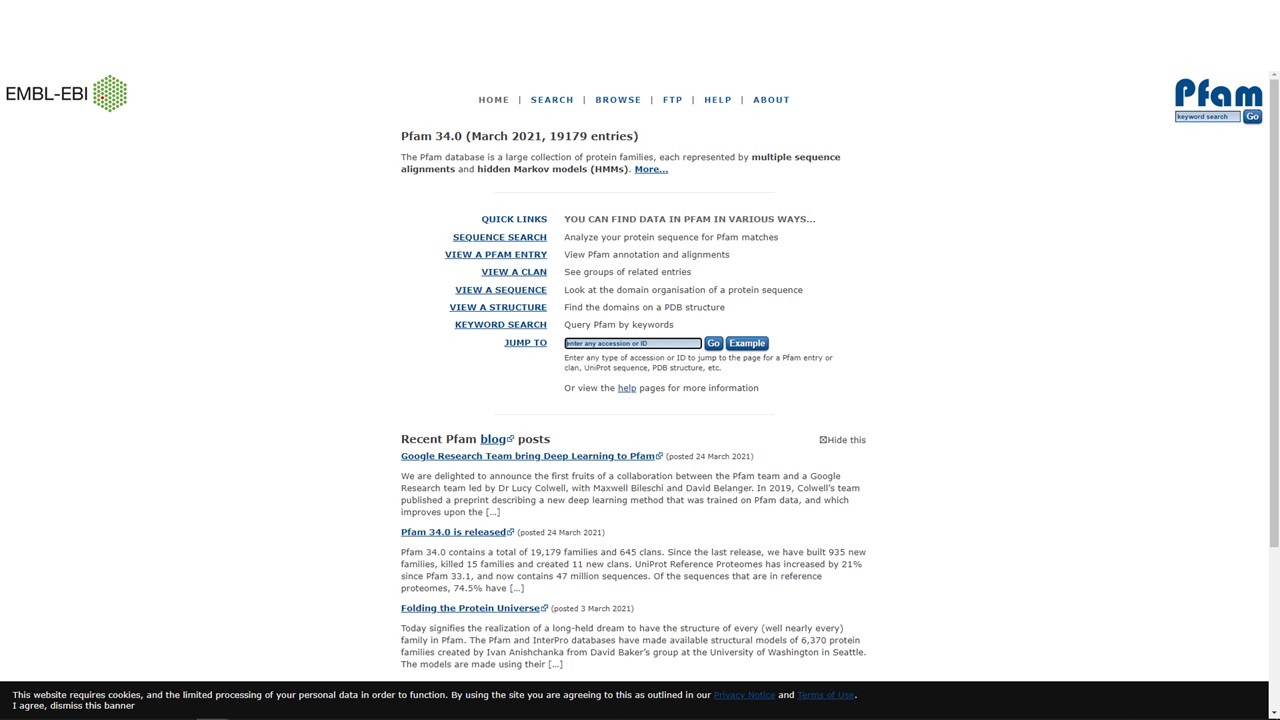
Figure 5.10: The Pfam database main page
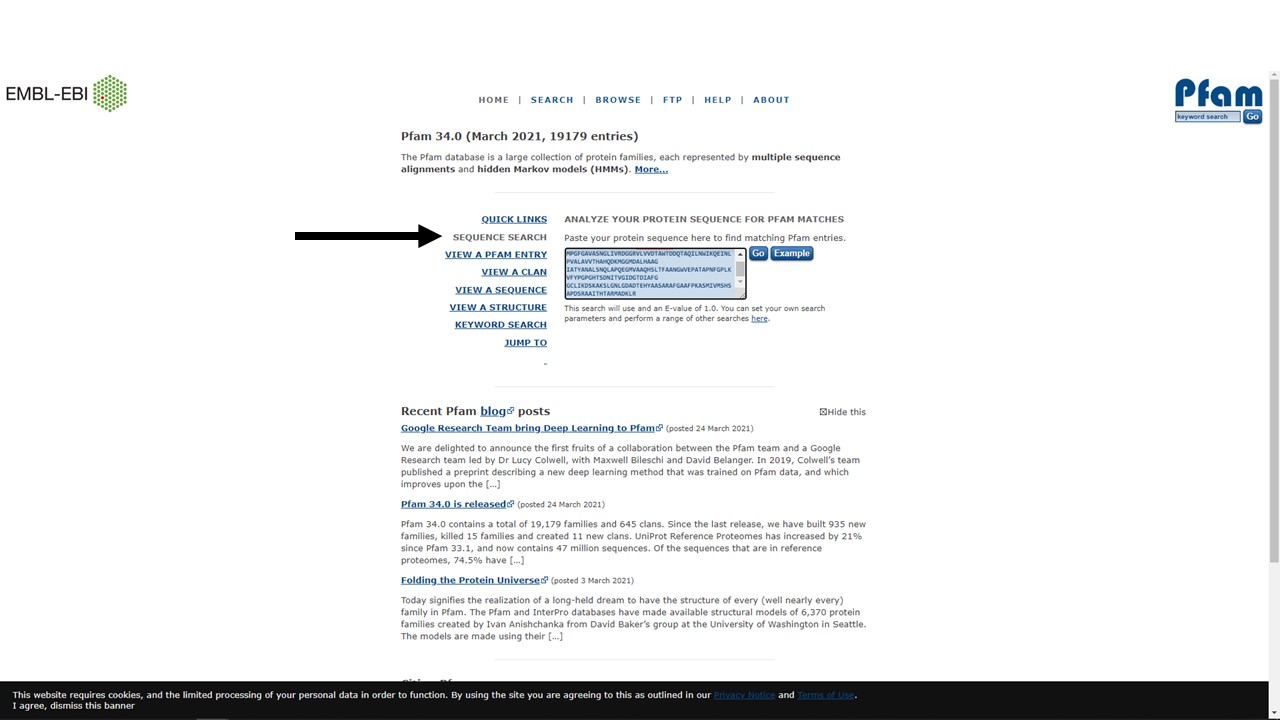
Figure 5.11: A Pfam sequence search using the NDM-1 amino acid sequence
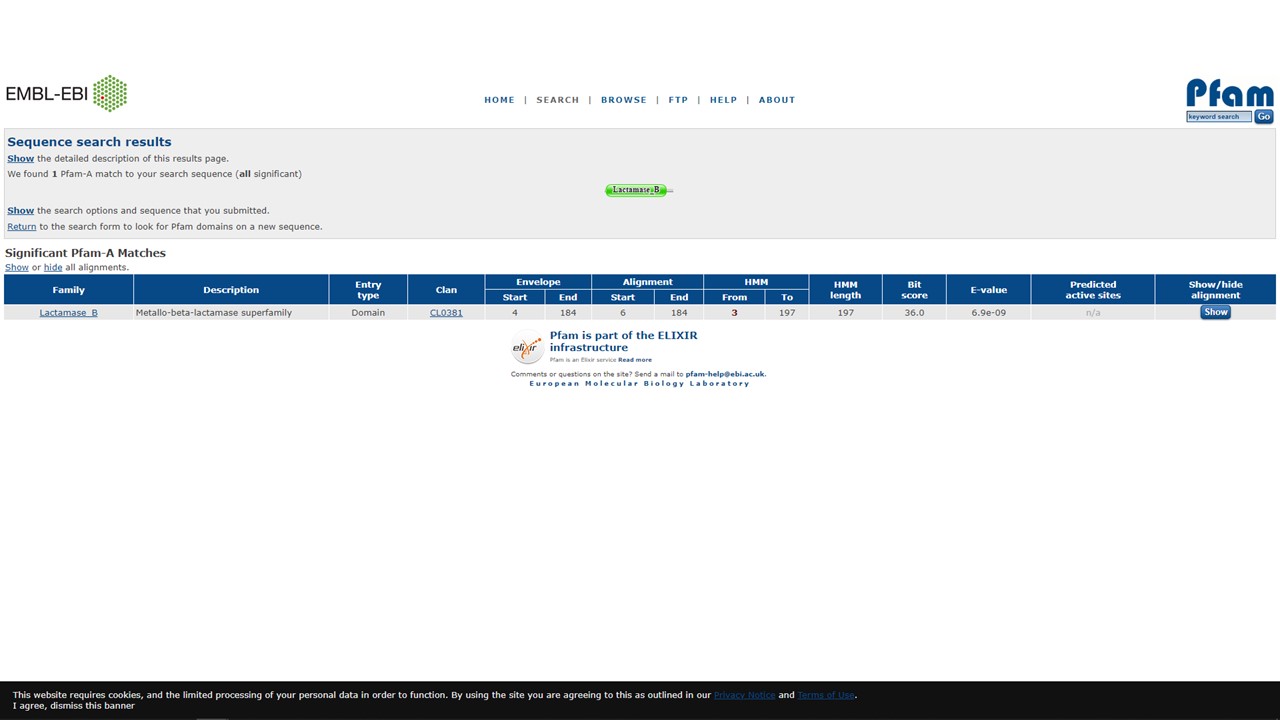
Figure 5.12: Pfam sequence search results
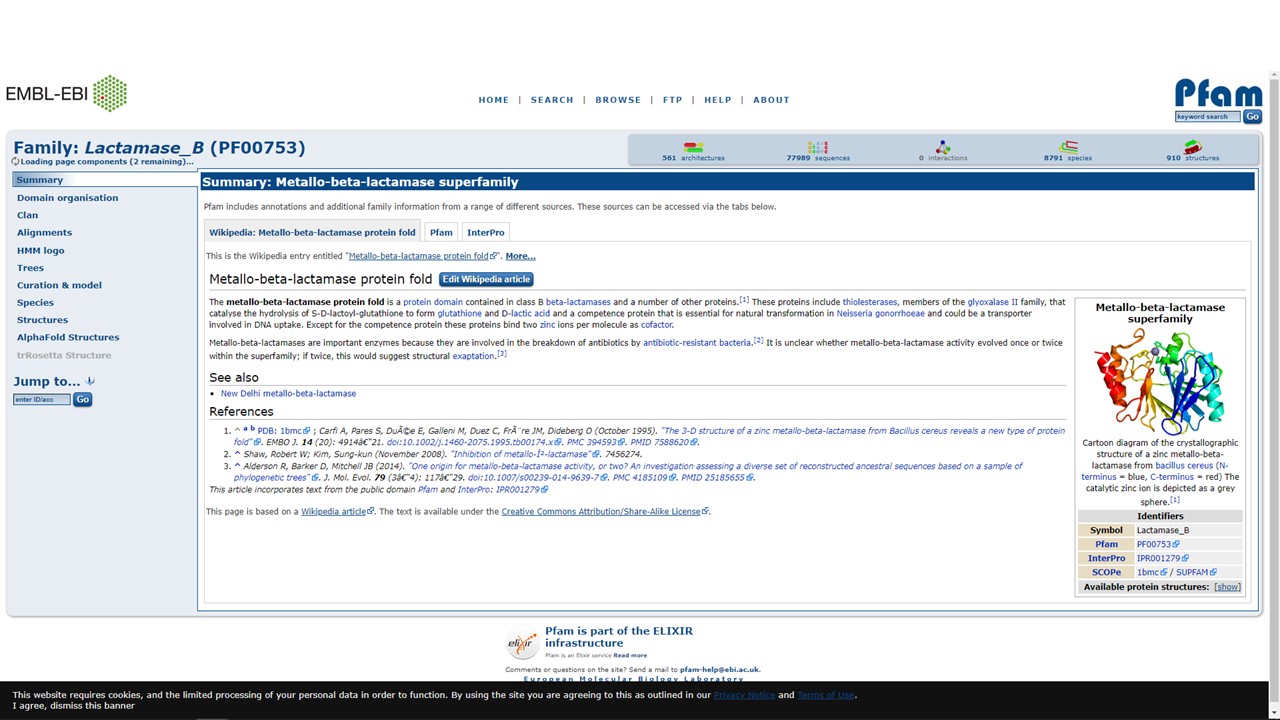
Figure 5.13: Pfam page for the Lactamase B family
Click to toggle an example of how to search the UniProt database (example of advanced search using Boolean terms)
We also want to find out what is known about NDM-1 function, i.e. the catalytic activity of the protein. For this, we will turn to the UniProt database at https://www.uniprot.org/.
We enter our keyword query “ndm-1” into the search bar at the top of the page. However, we specifically want to find more information about NDM-1 from K. pneumoniae, so we next click “Advanced” (instead of “Search”).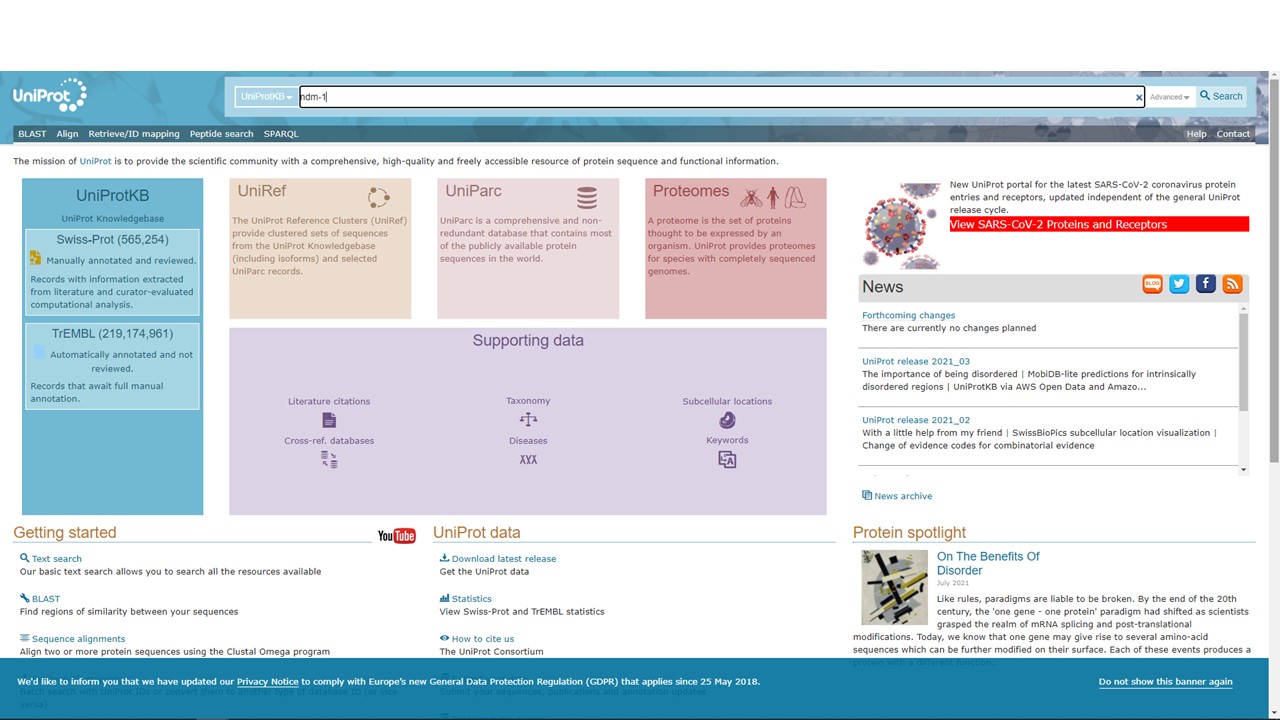
Figure 5.14: A UniProt search for ndm-1
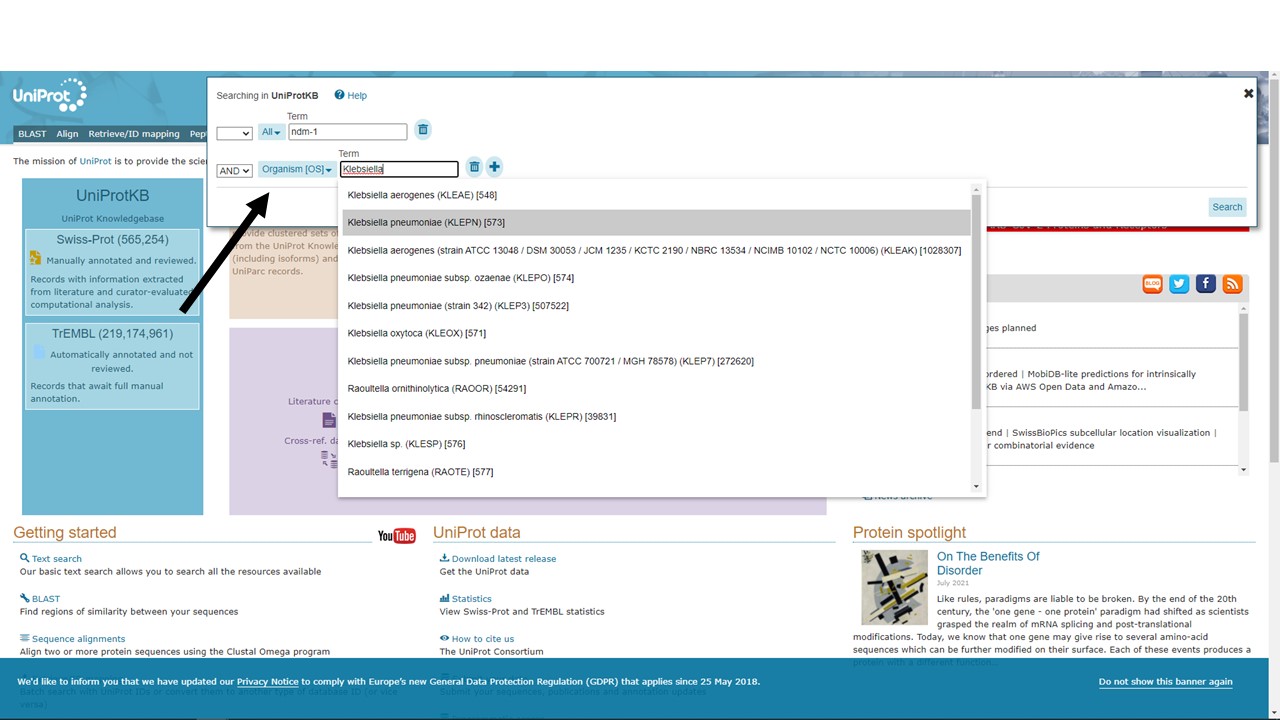
Figure 5.15: Building a UniProt Advanced Search
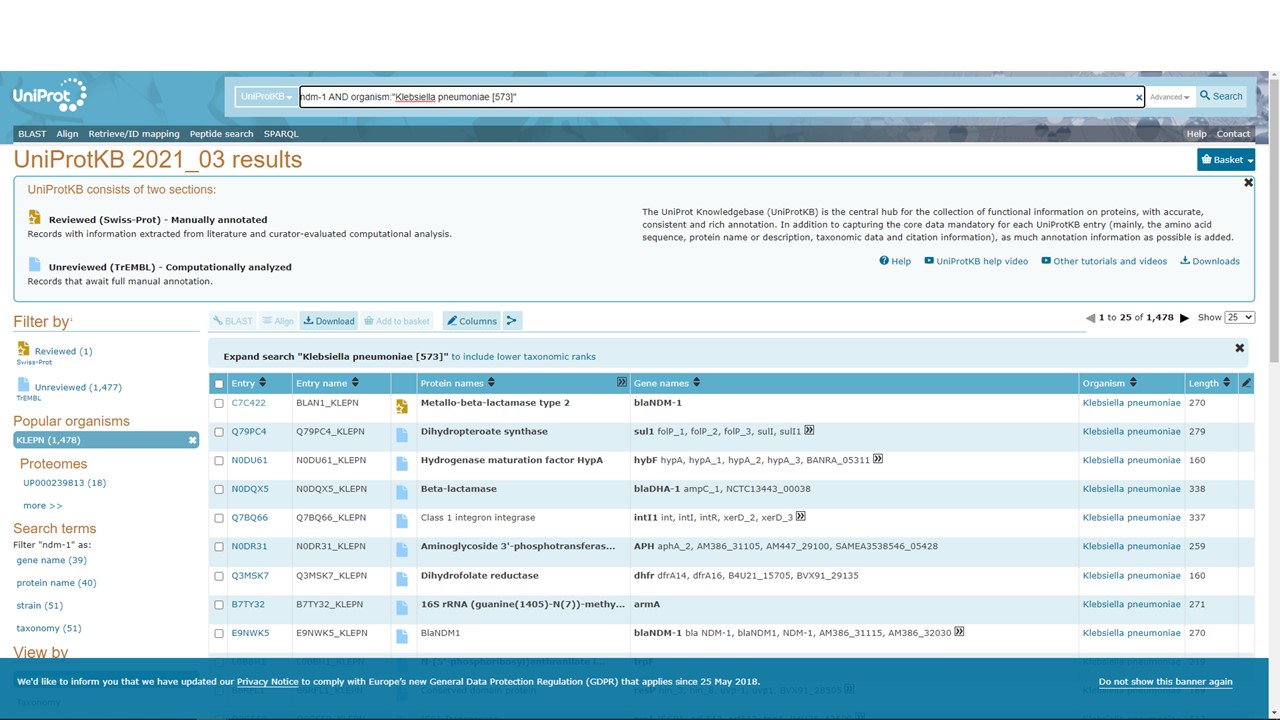
Figure 5.16: UniProt search results for ndm-1 proteins from Klebsiella pneumoniae
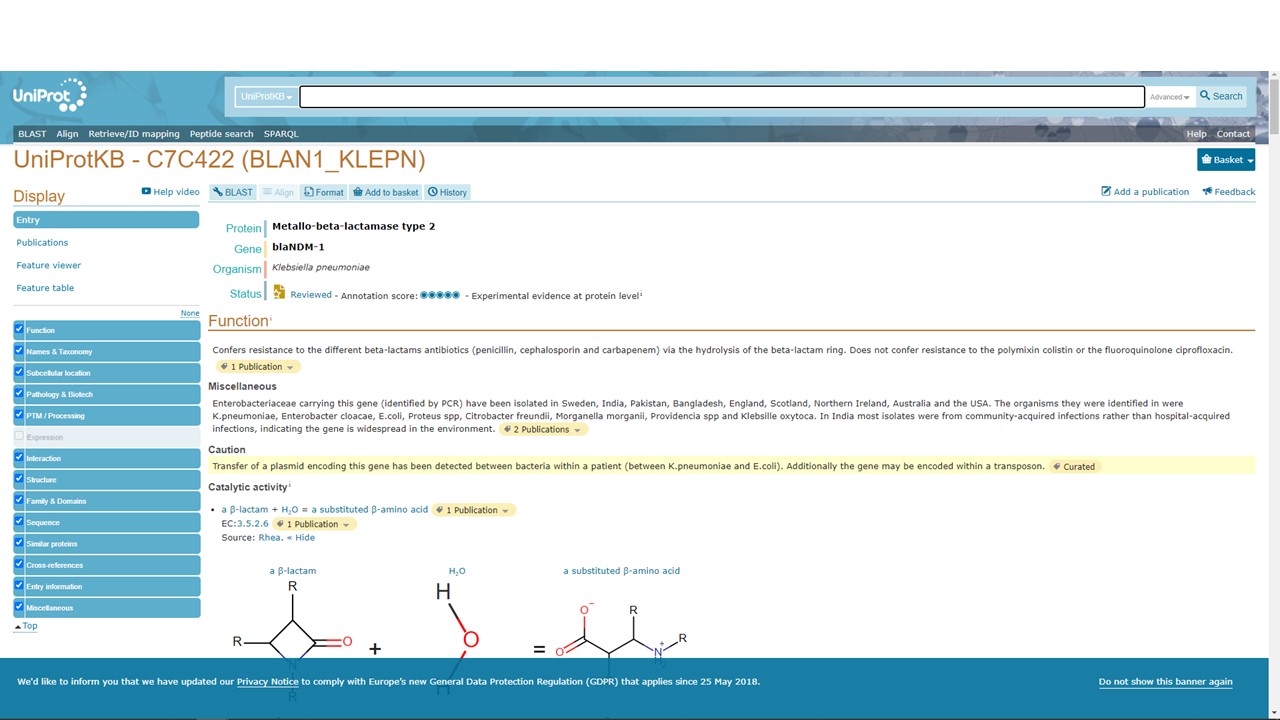
Figure 5.17: UniProt page for the K. pneumoniae NDM-1 protein