3 Shannon Index
This section introduces the Shannon Index as a simple measure of community diversity.
- We introduce the concept of Shannon Index and explain what it means.
- We walk through calculation of the Shannon Index in
R, using data from our example community in Chapter 2.- We relate the actions in our
Rwalkthrough to the equation for Shannon Index, at each step.
- We relate the actions in our
- We introduce the concept of Effective number of species in a community and how this relates to Shannon Index.
To understand diversity, we need to consider both richness and evenness, as described in Chapter 2.
We can obtain a simple count of species to calculate richness. But we also know that if each species is present in about the same abundance there is high evenness, and if the population is dominated by a single species there is low evenness. But, by itself, this idea of evenness does not give us a number that we can use to compare communities.
There are mathematical formulae that allow us to turn this concept of evenness into a number, and we can calculate such values for a community using R.
3.1 What is the Shannon index?
The Shannon Index (\(H\)) is arguably the simplest quantitative measure of community evenness/diversity, and is described by Equation 3.1. Shannon Index varies between:
- a value close to zero (for very uneven communities)
- the value \(\ln(N)\) for a community with \(N\) evenly-distributed species.
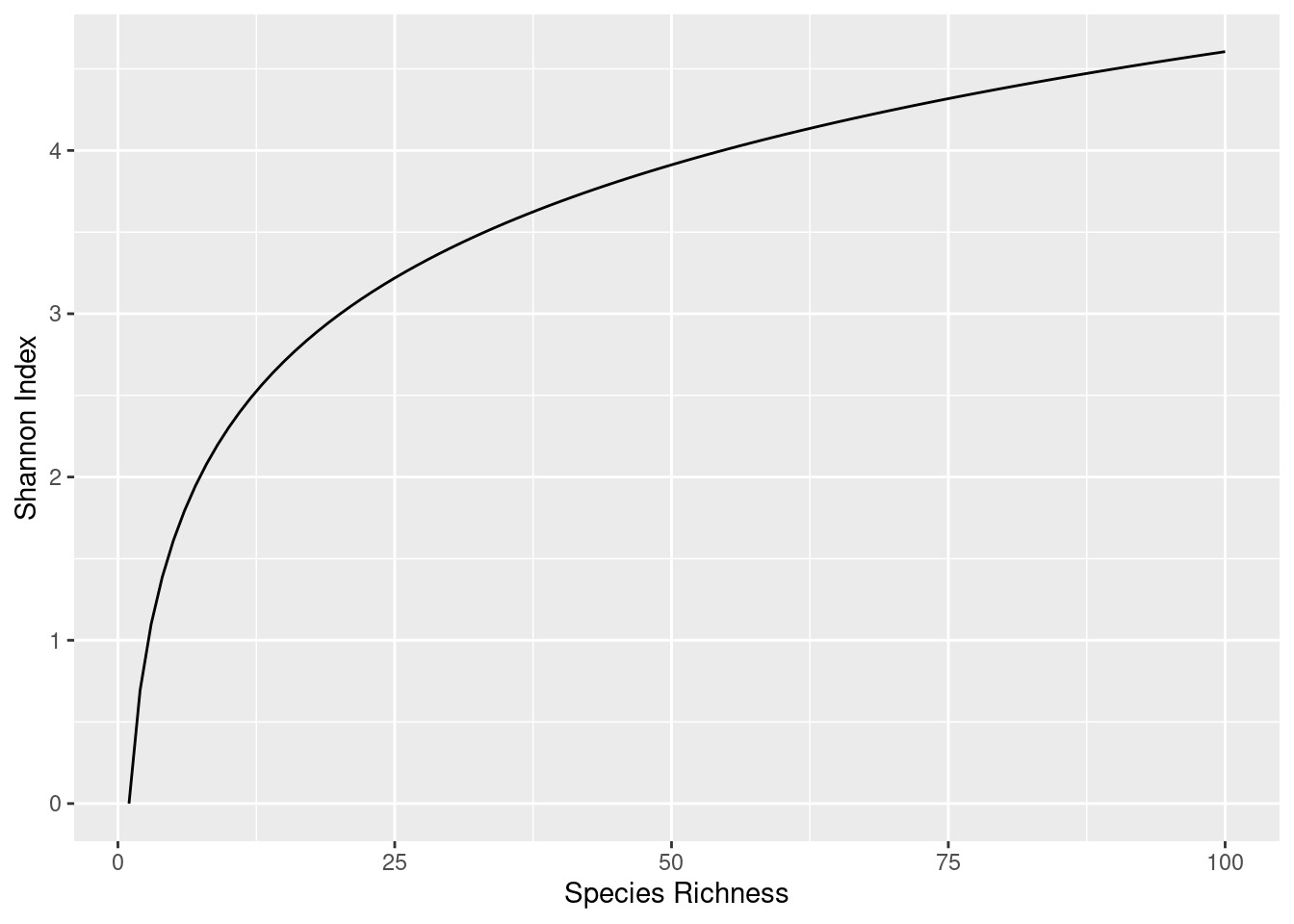
The way that the maximum value of Shannon Index varies with species richness (count of species) is shown in Figure 3.1.
3.1.1 What does the equation for Shannon Index mean?
The Shannon Index describes the evenness of species in a community. Representing a single species from the community as the letter \(i\), we can calculate the relative abundance of that species in the community as its abundance (the count of individuals from species \(i\)) divided by the total abundance for all species. We call this relative abundance \(p_i\) (this is the percentage of all individuals in the community that belong to species \(i\)).
Equation 3.1 takes this value (\(p_i\)) and transforms it into the Shannon Index, represented as \(H\). The resulting value varies between zero (maximally uneven, “not diverse”), and some maximum value (maximally even, “very diverse”), as represented in Figure 3.1. Knowing the richness (total number of species) for a community and the Shannon Index (\(H\)), we can quantify how diverse our community is.
\[ H = -\sum_{i=1}^{N} p_i \ln(p_i) \tag{3.1}\]
3.2 Calculating Shannon Index for our Mars Community
3.2.1 Collecting data about our community
Let’s start in R by defining our dataset for the Mars community.
In the code below we create two vectors: one of species names, and one of counts for those species in our sample (which we can get from Figure 2.3). We combine these vectors into a single dataframe, for convenience.
# Define a vector of species names
species <- c("Malteaser sp.", "Snickers sp.", "Twix sp.", "Mars sp.",
"Milky way", "Bounty sp.", "Galaxy choc", "Galaxy caramel")
# Define a vector of corresponding species counts
count <- c(3, 6, 6, 7, 7, 5, 3, 3)
# Bring these together in a dataframe
community.df <- data.frame(species, count)species | count |
|---|---|
Malteaser sp. | 3 |
Snickers sp. | 6 |
Twix sp. | 6 |
Mars sp. | 7 |
Milky way | 7 |
Bounty sp. | 5 |
Galaxy choc | 3 |
Galaxy caramel | 3 |
3.2.2 Calculating relative abundance
The first step in calculating Shannon Index is to calculate the relative abundance \(p_i\) of each species \(i\). To do this, we calculate the percentage of the entire community that is made up from each species, as below. We divide the count for each species by the sum of counts for all species (i.e. the total number of individuals, in this case).
# Calculate relative abundances
community.df$rel_abd <- community.df$count / sum(community.df$count)species | count | rel_abd |
|---|---|---|
Malteaser sp. | 3 | 0.075 |
Snickers sp. | 6 | 0.150 |
Twix sp. | 6 | 0.150 |
Mars sp. | 7 | 0.175 |
Milky way | 7 | 0.175 |
Bounty sp. | 5 | 0.125 |
Galaxy choc | 3 | 0.075 |
Galaxy caramel | 3 | 0.075 |
CautionMathematical Content!
How does what we’ve just done in R relate to Equation 3.1?
For each of our species (denoted by \(i\) in the equation), we have calculated the relative abundance \(p_i\), which is used in the parts of Equation 3.2 indicated in red, below.
\[ H = -\sum_{i=1}^{N} \color{red}{p_i} \color{black}{\ln( \color{red}p_i \color{black})} \tag{3.2}\]
3.2.3 Calculating Shannon Index
To turn this data into the Shannon Index, we need to carry out two more steps: calculate the natural log of the relative abundance of each species (\(\ln(p_i)\)), then multiply this by the corresponding relative abundance (\(p_i\)), as in the R code below:
# Calculate the natural log of relative abundance
community.df$ln_rel_abd <- log(community.df$rel_abd)
# Multiply the relative abundance by its natural log
community.df$mult <- community.df$rel_abd * log(community.df$rel_abd)species | count | rel_abd | ln_rel_abd | mult |
|---|---|---|---|---|
Malteaser sp. | 3 | 0.075 | -2.590267 | -0.1942700 |
Snickers sp. | 6 | 0.150 | -1.897120 | -0.2845680 |
Twix sp. | 6 | 0.150 | -1.897120 | -0.2845680 |
Mars sp. | 7 | 0.175 | -1.742969 | -0.3050196 |
Milky way | 7 | 0.175 | -1.742969 | -0.3050196 |
Bounty sp. | 5 | 0.125 | -2.079442 | -0.2599302 |
Galaxy choc | 3 | 0.075 | -2.590267 | -0.1942700 |
Galaxy caramel | 3 | 0.075 | -2.590267 | -0.1942700 |
CautionMathematical Content!
Here’s how these two actions relate to Equation 3.1.
Firstly, for each of our species, we calculated the natural log of the relative abundance: \(\ln(p_i)\), shown in red in Equation 3.3 - this is column ln_rel_abd in the dataframe.
\[ H = -\sum_{i=1}^{N} p_i \color{red}{\ln(p_i)} \tag{3.3}\]
Next, we calculated the product of \(p_i\) and \(\ln(p_i)\), highlighted in orange in Equation 3.4 - this is column mult in the dataframe.
\[ H = -\sum_{i=1}^{N} \color{orange}{{p_i} \ln(p_i)} \tag{3.4}\]
The Shannon Index is then the sum of this final column of values (multiplied by -1 to make it a positive value).
shannon_index = -sum(community.df$mult)
shannon_index[1] 2.021916
CautionMathematical Content!
Summing the product \(p_i \ln(p_i)\) for each species \(i\), and multiplying it by \(-1\) is indicated by the part of Equation 3.5 highlighted in red.
\[ H = \color{red}{-\sum_{i=1}^{N}} \color{black}{p_i \ln(p_i)} \tag{3.5}\]
3.2.4 Understanding the Shannon Index
So, we have a number \(H = 2.02\) as the Shannon Index for our sample. How do we interpret this?
Remember from earlier that the maximum Shannon Index - corresponding to maximum diversity - for a sample with eight species is \(\ln(8) = 2.08\). The value we calculated here, \(H = 2.02\), is close to this value and so we can conclude that our sample is very diverse.
There is another way to think about this number, called the effective number of species.
3.3 The Effective Number of Species for a community
We can use the Shannon Index to calculate a value known as the effective number of species for a community. This name reflects that, although a community might contain a certain number of species, if some species are only present in very low abundance, they are not contributing significantly to the community, and they are effectively not present, and the effective number of species is less - maybe much less - than the richness of the community.
For example:
- A community with three species in equal proportions, e.g. 33% \(A\), 33% \(B\), and 33% \(C\) clearly has three equally-contributing species. We might expect the effective number of species to be three.
- A community dominated by a single species, e.g. 1% \(A\), 1% \(B\), and 98% \(C\) might effectively have only one species: species \(C\).
By taking the exponential of the Shannon Index, we calculate a value known as the effective number of species, or Diversity (\(D\)) of a community. The mathematical equation is given in Equation 3.6.
\[ D = \exp(H) \tag{3.6}\]
CautionMathematical content
This works because, as we noted earlier, a community with \(N\) evenly-represented species has a Shannon Index of \(H = \ln(N)\). Hence, when this is true:
\[ D = \exp(H) = \exp(\ln(N)) = N \]
and so, in this special case of absolute evenness, effective number of species is the same as the actual number of species.
3.3.1 The Effective Number of Species for our Mars sample
The Shannon Index for our Mars sample was \(2.021916\), and we can use R to calculate a corresponding Diversity value \(D\) by taking the exponential of this number:
diversity = exp(2.021916)
diversity[1] 7.552782This gives a value of \(D = 7.55\) for the effective number of species. This is close to the actual number of species in our sample - the richness value - of eight, which indicates that our sample is highly diverse.
3.4 Exercises
ExerciseExercise 1
Suppose we have an oral microbiome community with the following genus-level composition, and abundances/counts:
- Abiotrophia: 1.27e4
- Peptostreptococcus: 1.84e3
- Corynebacterium: 2.41e5
- Eubacterium: 4.92e3
- Moraxella: 7.31e4
- Neisseria: 1.88e6
- Campylobacter: 8.23e4
- Desulfovibrio: 3.11e6
Use the interactive R box below to calculate the Shannon Index and the Effective Number of Species in the community.
How diverse or even is the community? Justify your answer.
(Click to expand answer)
AnswerAnswer
The Shannon Index for this community is \(H = 0.97\), and the Effective Number of Species is \(D = 2.64\).
As we know there are eight species (technically-speaking, taxonomic genera) in the community, and the effective number of species is much lower than this, we would conclude that the community is uneven/not very diverse, and dominated by a small number of genera.
TipExample solution code
# Create a dataframe describing the community
dfm <- data.frame(species=c("Abiotrophia", "Peptostreptococcus",
"Corynebacterium", "Eubacterium", "Moraxella",
"Neisseria", "Campylobacter", "Desulfovibrio"),
count=c(1.27e4, 1.84e3, 2.41e5, 4.92e3, 7.31e4, 1.88e6,
8.23e4, 3.11e6))
dfm$p.i <- dfm$count / sum(dfm$count)
dfm$h.i <- dfm$p.i * log(dfm$p.i)
# Calculate the Shannon Index and Effective Number of Species
H = -sum(dfm$h.i)
D = exp(H)
c(H, D)
ExerciseExercise 2
The stacked bar chart below represents the distribution of species in a community.
Use the slider in the interactive graph to visualise different communities containing the same six species, but having different counts in each community, then consider the questions below.
Use the Plot and the Data tabs to understand what’s going on with the data.
- Compare communities 1 and 2. What is more important for Shannon Index (\(H\)) and Effective Number of Species (\(D\)): count, or relative proportion?
- Do you think that relative proportion is estimated more accurately for large or small counts? How would that affect estimates of \(H\) and \(D\) in communities with a small number of members?
- Compare communities 3 and 5. Are \(H\) and \(D\) similar for these communities? Do their populations have the same distribution?
- Is having a similar Shannon Index and/or Effective Number of Species sufficient to say that two communities are similar?
(Click to expand answer)
AnswerAnswer
- Both communities 1 and 2 are completely even, with \(H=1.79\) and \(D=6\). The population size of community 2 is 10,000 times that of community 1. Relative proportion is more important than counts of individuals.
- With a small population, the effect of miscounting on proportion of a species may be more significant. Miscounting 10 individuals for a species is unlikely to affect calculations much if there are 1,000 individuals of that species. But if there were only 20, the effect would be very large. Counting errors are often a constant size, so more significant in small populations, and more likely to introduce noise to the estimate of diversity.
- The values of \(H\) (1.66 in both cases) and \(D\) (5.27 for community 3 and 5.25 for community 5) are similar. However, community 5 has four species with equally large, and two with equally small abundance. Community 3 has six species with different abundances. They are not the same distribution.
- The answers above show that: (i) \(H\) and \(D\) do not inform us about the overall size of the population; (ii) populations with different distributions of species can give the same values of \(H\) and \(D\). These are significant differences and sharing the same Shannon Index or Effective Number of Species is not enough to say that two populations are the same.