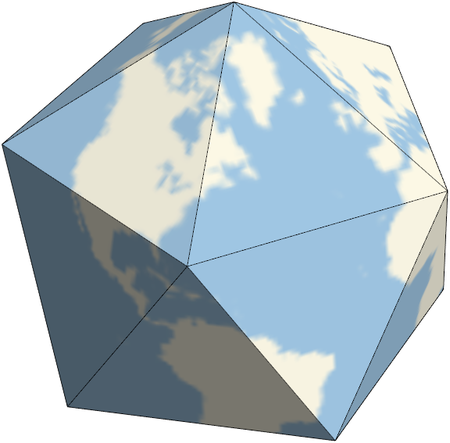
Of course, the Earth isn’t a tetrahedron, but an oblate spheroid, and there are an infinite number of points we could measure on its surface, not just four distinct faces. To get closer to this shape, we’re going to change our model from a tetrahedron to another regular Platonic solid: am icosahedron, with 20 faces.
Figure 28.1: The Earth, projected onto an icosahedron. Image by John D. Cook
Note
Changing our model of the Earth to Icosahedron Earth, with 20 faces, is still artificial. But it will allow us to see the shape of the probability distribution as we change the number of samples we take, more clearly.
28.1 Calculating probabilities
We define that Icosahedron Earth has 20 faces, with each face being either “water” (W) or “land (L). This implies that there are 21 possibilities, from”all water,” through “one land, 19 water,” all the way to “all land.” It would take us quite a while to calculate out and show the possibilities explicitly. Happily, being in the age of modern computational statistics we can use the R language1 to do the calculations for us and visualise the result.
28.1.1 Testing Tetrahedron Earth
The code below calculates these probabilities for our observations in Chapter 25, on Tetrahedron Earth:
# Return the posterior distribution of p, the proportion of points (faces) # on the planet's surface that are water, given a sample in the form# c("W", "L", "W") and a number of faces.# By default the number of faces is four, representing Tetrahedron Earth.# Adapted from Statistical Rethinking, by Richard McElreath# (https://www.youtube.com/watch?v=R1vcdhPBlXA)compute_posterior <-function(sample, faces=4, round_to=3) { W <-sum(sample =="W") # Waters observed L <-sum(sample =="L") # Lands observed possibilities = faces +1# Number of possible probabilities proportions =seq(0, 1, length.out=possibilities) # The possibile proportions of water# Calculate the number of ways the sample data could be generated ways <-sapply(proportions, function(q) (q * faces) ^ W * ( (1-q) * faces ) ^ L )# Calculate the posterior distribution posterior <- ways/sum(ways)# Return a data.frame of the possibilities and waysdata.frame( proportion=factor(proportions), ways,probability=round(posterior, round_to))}# The observations we have already madeobservations <-c("L", "W", "L", "L", "W", "W", "W", "L", "W", "W")# Calculate the resulting distributiondistn_tetra <-compute_posterior(observations, 4)# Tabulate the resultdistn_tetra |>kbl(format="html", align="c") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width = F)
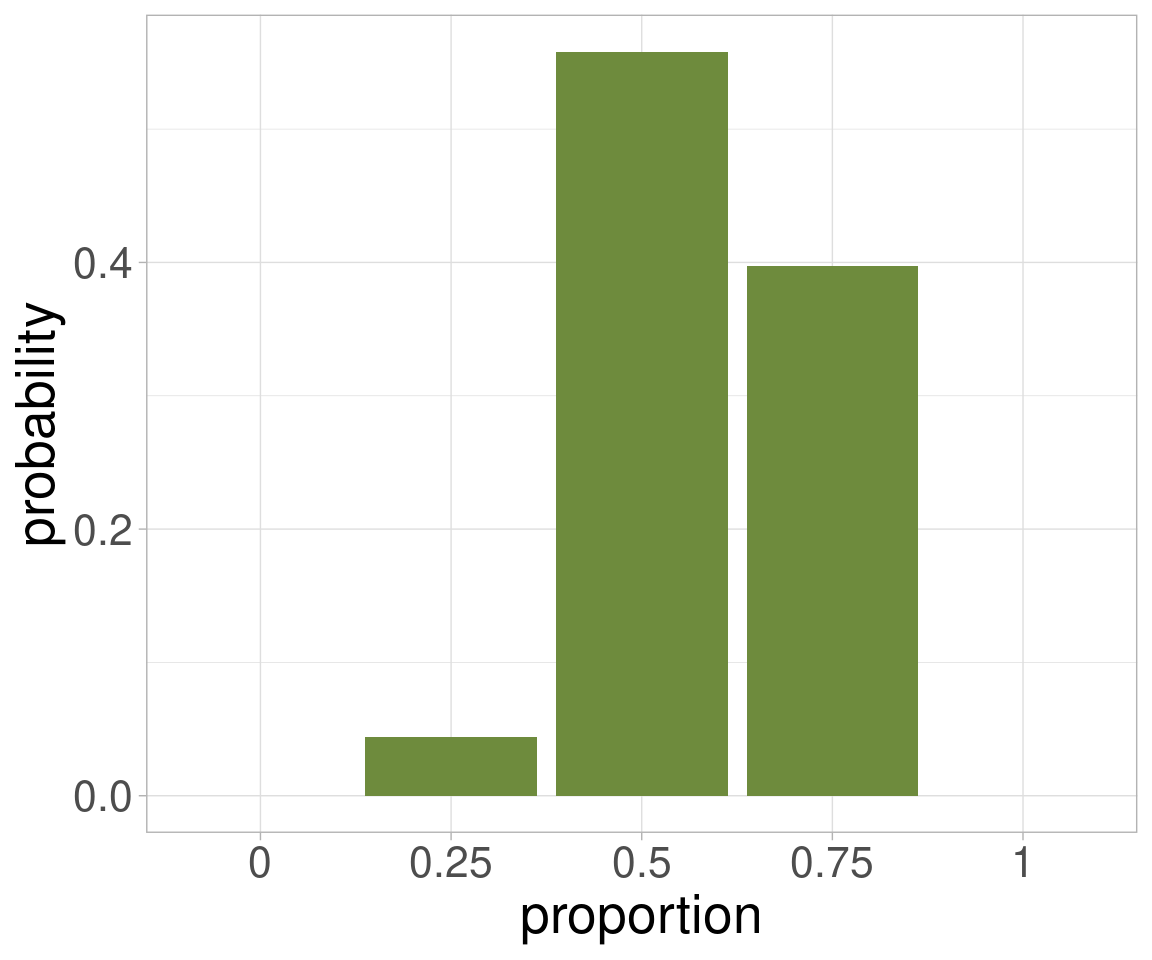
Table 28.1: For Tetrahedron Earth, each possibile proportion of surface water, the corresponding ways the observed outcome could be generated, and the posterior probability that the Tetrahedron Earth we sampled from has that proportion of surface water.
proportion
ways
probability
0
0
0.000
0.25
81
0.044
0.5
1024
0.558
0.75
729
0.397
1
0
0.000
As we are using modern computational statistics in R, we can also visualise the distribution using the code below, in Figure 28.2.
Show the code
# Show the Tetrahedron Earth distribution as a histogramggplot(distn_tetra, aes(x=proportion, y=probability)) +geom_col(fill="darkolivegreen4") +theme_light() +theme(text =element_text(size=20))
Figure 28.2: A histogram of the probabilities that each possible form of Tetrahedron Earth could have produced the observed sequence of observations.
We can see visually and intuitively in Figure 28.2 that the posterior probability distribution skews to the right, and there is not much to choose between the 50% and 75% water planets.
Important
Our analysis here, as is the case for traditional frequentist analysis, does not give us a single point value as output to tell us “this form of Tetrahedron Earth is the one that generate the observed sample data. It gives us a probability distribution that we then must interpret.
You are probably used to interpreting the outputs of t-tests and similar statistical analyses in terms of whether a probability is greater or less than some threshold value. It is important to recognise that this probability comes from a distribution of possibilities as well. The difference here is that we are making that distribution explicit, and not applying a threshold.
28.1.2 Probabilities for Icosahedron Earth
We wrote the code above to calculate posterior probabilities in R, and so we can reuse the code to investigate circumstances different to Tetrahedron Earth. Specifically, we are interested to know what happens if we have a “more realistic” (but still highly artificial) model: Icosahedron Earth, with 20 faces that are either “water” or “land”. We can calculate this using the code below.
Show the code
# Calculate posterior probabilities for Icosahedron Earthdistn_icosa <-compute_posterior(observations, faces=20)# Show the Tetrahedron Earth distribution as a histogramggplot(distn_icosa, aes(x=proportion, y=probability)) +geom_col(fill="darkolivegreen4") +theme_light() +theme(text =element_text(size=10))
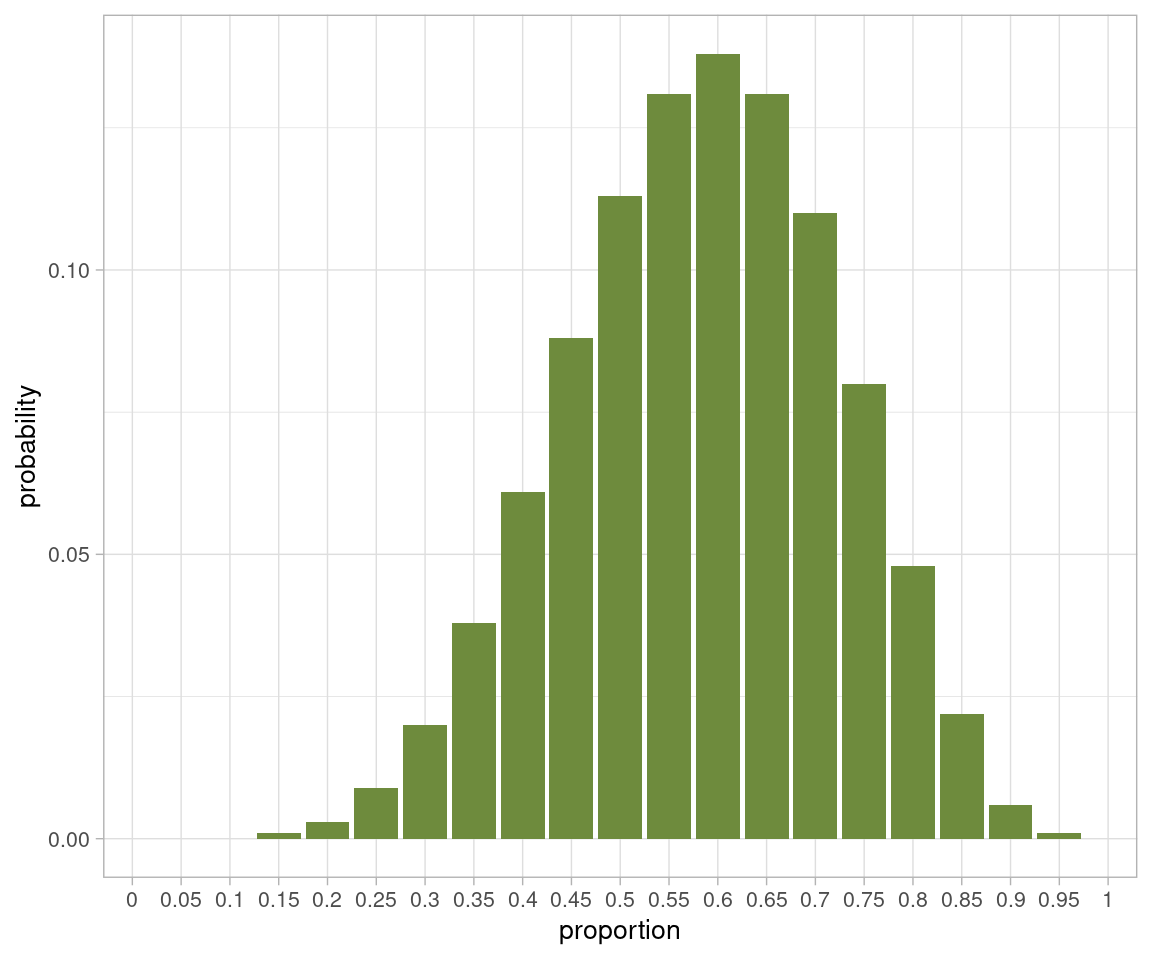
Figure 28.3: A histogram of the probabilities that each possible form of Icosahedron Earth (with 20 faces) could have produced the observed sequence of observations.
Visually we can now see that the distribution is much smoother and starts to resemble the parametric probability distributions you might already be familiar with.
TipInterpreting the distribution
The distribution in Figure 28.3 is much more informative than that in Figure 28.2. The overall shape of the probability distribution is clearer, and we can see it looks like a skewed bell shape, with a modal2 value of 0.6, implying that the most likely surface water distribution is 60% of the surface of Icosahedron Earth.
We can also see that the bulk of the estimates lie between 0.45 and 0.75, suggesting that the analysis is most confident that the true distribution lies somewhere between these values3.
Important
We haven’t increased the number of samples we have taken or values we have observed
We have only made our model Earth more representative of the “real” situation of an oblate spheroid Earth.
Warning
Although the estimate of the most likely value for \(p\) has become more precise, the y-axis tells us that the probability of any specific value of \(p\) being the “true” value has fallen, and the relative probability of nearby possible values for \(p\) is very similar.
28.1.3 What if we used a larger number of faces?
We might think that if we continue to increase the level of detail in our model, we will keep increasing the precision of our estimate. We can see what the distribution would look like for a model Earth with 100 faces, using the code below.
Show the code
# Calculate posterior probabilities for Icosahedron Earthdistn_hundo <-compute_posterior(observations, faces=100, round_to=5)# Show the Tetrahedron Earth distribution as a histogramggplot(distn_hundo, aes(x=proportion, y=probability)) +geom_col(fill="darkolivegreen4") +theme_light() +theme(text =element_text(size=10)) +scale_x_discrete(breaks=seq(0, 1, 0.1))
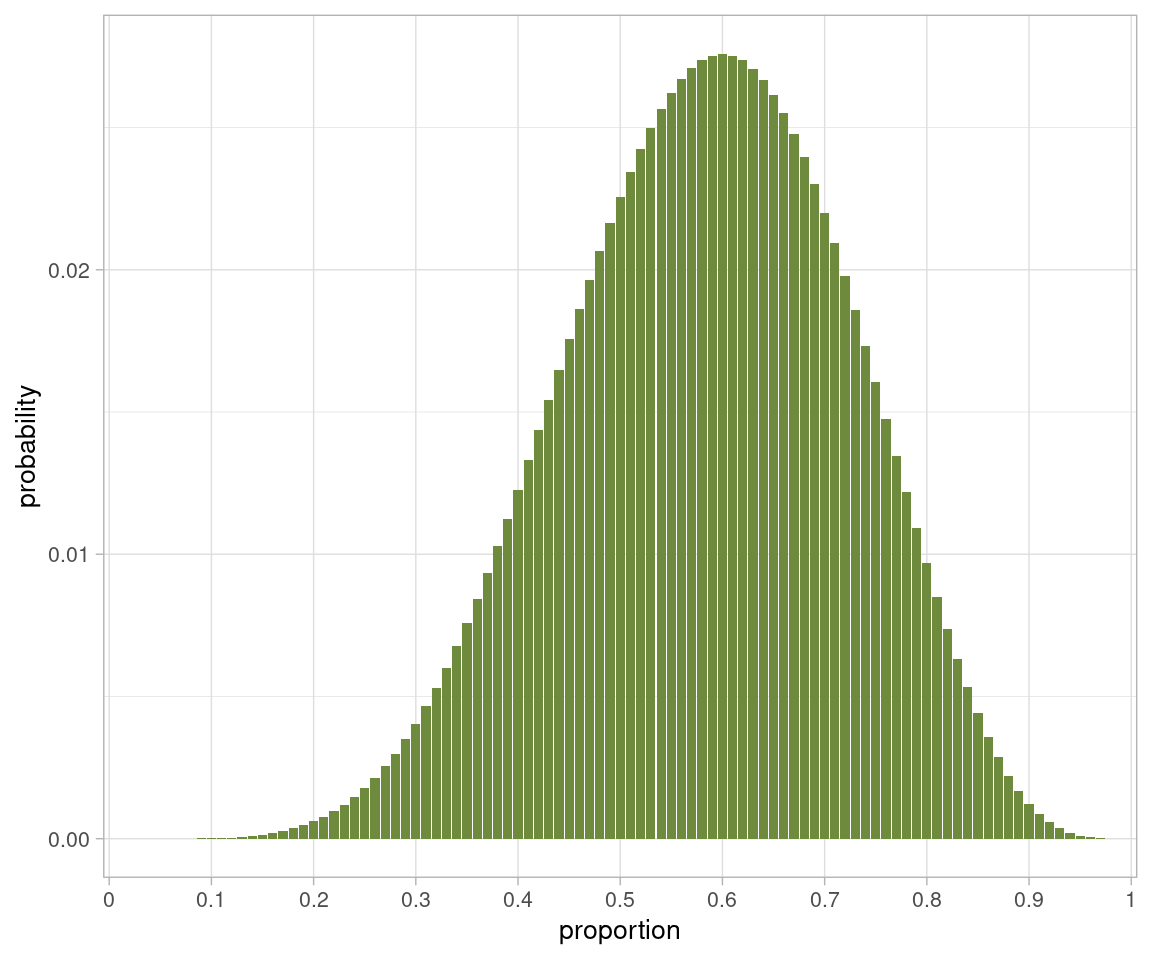
Figure 28.4: A histogram of the posterior probabilities, using an Earth with 100 faces.
We do see that the estimate of the most likely proportion \(p\) is more precise, but the relative probability of nearby values is also very similar.
Important
When changing the number of faces used to represent the Earth, there is a trade-off between the precision of our estimate of the most likely proportion \(p\), and our confidence in that estimate being the most likely proportion.
This entire online book is written in the R language. It’s rather powerful and flexible.↩︎